想必大家平常做SEO的过程中多少会买点外链,毕竟是获取外链最容易的方式。但是其中有好多坑,不知道大伙知不知道?今天就来写一篇文章来帮大家避坑。
一、明显的坑
1、高DA/DR/AS,低流量
单纯看DA没啥用,有一大堆DA很高、但是流量见底的垃圾网站。DA完全可以用一小点钱就可以刷到五六十,所以不要迷信这个值。
2、流量跳楼式下降,趋于见底或是流量上天入地般变动
这种多半是被谷歌惩罚的网站,这种外链百害无一利。
3、域名年龄特短
几个月、甚至一两年域龄的网站,基本不靠谱。多半AI站点,很可能不久就挂掉。
4、backlinks几百W条
域名历史很短的网站,有几十W、几百W条入站外链,基本都是垃圾外链堆起来的。迟早药丸。
二、技术向的坑
有时候可能好不容易遇到几个各项指标还算过得去的网站,这时不要冲动,还需再做个检查。
1. nofollow
这个坑倒是很容易识别,毕竟大部分有点外链知识的人买了外链后都会检查,很容易发现。当然,nofollow要检查两处:
①检查锚文本<a>中是否有nofollow
②检查页面<head>中是否有nofollow —— 这个可能也有挺多人忽略掉。
并不是说nofollow外链一无是处,对我们的整体外链结构健康度还是挺有帮助的;但是,把nofollow当成dofollow来忽悠我们,这是无法接受的。
很多时候,我们检查了nofollow后便觉得ok了,其实不然,还有更多的坑。
2. noindex
如下图,这是在页面<head>中,写给爬虫的标记,表示这个页面不能被收录。当爬虫看到noindex标记时基本不会爬取这个页面,也就不知道我们在这个页面中放了链接,那我们的外链即便是dofollow的,依然是做了也是白做。

3. canonical标记的url与当前页不一致
canonical用来告诉搜索引擎当前页与标签内url页面雷同,希望搜索引擎索引指定的页面。当然谷歌实际上不会完全采信这个标签,但是依然可能会对当前页面的收录有影响。
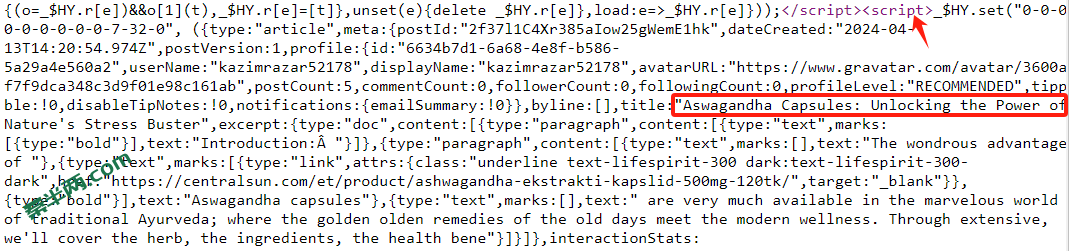
4. 页面主体内容全部由JaveScript提供
见下图。正常我们的文本是包裹在<p>或<div>标签内,假如所有文本都在<script>标签内,谷歌不一定会去执行JS脚本,所以有可能不会被收录。
5.robots.txt禁止url路径
这是一个挺隐蔽的点。正规爬虫是会遵循robots协议的,那么当robots文件中禁止爬虫爬取某些url路径,那么谷歌的爬虫压根就不会抓取这些页面的内容。检查路径:xxx.com/robots.txt .

三、去哪购买外链?
我一般在 Fiverr 上购买。但是注意识别,上面有大量垃圾外链,之前用脚本跑了一遍人家提供的包含几百条外链的列表,发现基本都是被惩罚的垃圾外链。
不过,按照我这篇文章的辨别方法来筛选外链,并从注册年份比较长、评分比较高的卖家那里购买,就基本没啥问题的。
还需记住一个原则:正常的外链通常一条$50+至几百刀不等;便宜基本没好货。(这里的一条是指购买一篇Guest Post或是在已有文章中插入链接;在这些文章中一般允许我们放1-3条指向我们网站的链接)。